This blog-post relates to a meeting entitled “Modelling Challenges in Cancer and Immunology: one-day meeting of LMS MiLS”. The meeting was held at the beautiful location of Kings College London. The talks were a mix of mathematical modelling and experimental – with most combining the two disciplines together. The purpose of the meeting was to foster new collaborations between the people at the meeting.
Collaboration is a key aspect of this intersection between cancer and immunology since no one person can truly have a complete understanding of both fields, and nor can they possess all the skill-sets needed. When collaborating though each of us trusts the experts in their respective fields to bring conceptual models to the table for discussion. It’s very important to understand how these conceptual models have developed over time.
Every scientist has developed their knowledge via their own interpretation of the data/evidence over their careers. However, the uncertainty in the data/evidence used to make statements such as A interacts with B is rarely mentioned.
For many scientists, null hypothesis testing has been used to help them develop “knowledge” within a field. This “knowledge”, throughout that scientists’ career, has been typically gained by using a p-value threshold of 0.05 with very little consideration of the size of effect or what the test actually means.
For example, at the meeting mentioned there was a stream of statements, which were made to sound like facts, on correlations which were tenuous at best simply because the p-value was below 0.05. An example is the figure below, where the data has a correlation coefficient of 0.22 (“p<0.05”). The scientist from this point onwards will say A correlates with B consigning the noise/variability to history.
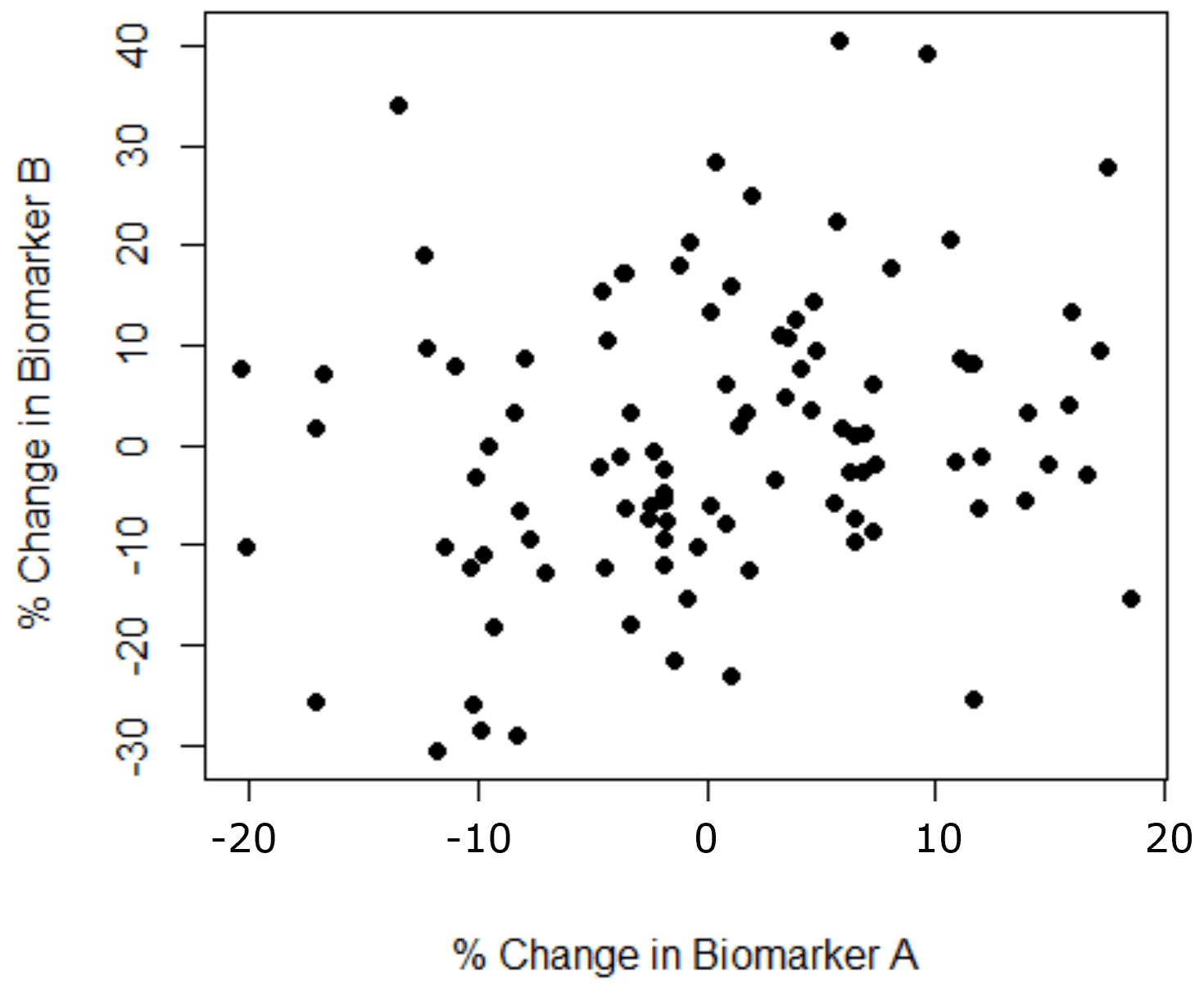
Could it be that the conceptual models we discuss are based on decades of analyses described as above? I would argue this is often the case and was certainly present at the meeting. This may argue for having very large collaboration groups and looking for consensus, however being precisely biased is in no-one’s best interests!
Perhaps the better alternative is to teach uncertainty concepts at a far earlier stage in a scientist’s career. That is introducing Bayesian statistics (see blog-post on Bayesian Opinionater) earlier rather than entraining scientists into null-hypothesis testing. This would generally improve the scientific process – and will probably reduce my blood pressure when attending meetings like this one.